Moins de poudre de perlimpinpin, plus de contexte
Ce texte est une traduction de l'excellent Less Snake Oil, More Context par Surma.
Obtenir de bonnes performances sur le web est un défi permanent. Les développeur·ses essaient et essaieront encore d'en repousser les limites et c'est une bonne chose. Je ne veux pas changer cela.
Je veux changer comment nous — en tant que communauté — approchons, analysons et comprenons les problèmes de performances. Je vois souvent des questions du type « Quel est la meilleure manière de faire X ? », « Quel bibliothèque est la plus rapide pour réaliser Y ? ». Il semble que nous aimions les superlatifs mais lorsqu'il s'agit de performance, ils peuvent être contre-productifs.
Appliquer généreusement la poudre de perlimpinpin aux zones concernées
ou autrement dit « Des règles pas des outils ». Alex Russell a utilisé « Poudre de perlimpinpin » dans un tweet (NDT: Alex Russel étant anglophone, il a utilisé Snake oil) et je pense que cette expression transmet parfaitement à la fois l'opacité et le manque de fiabilité de ce type de traitement.
Quelques exemples :
- Une animation est saccadée. Utilisez
will-change: transformsur l'élément animé. - N'utilisez pas
forEach(), les bouclesforsont plus rapides. - Pour une chargement plus rapide, groupez les ressources.
- N'utilisez pas le sélecteur
*car il est lent.
Tout ceci est vrai dans un contexte particulier. Il faut bien comprendre une chose : la lenteur ou une animation saccadée n'est qu'un symptôme, pas une maladie. Ce qui est donc nécessaire ici, c'est une procédure de diagnostique différentiel. La fluidité d'une animation peut être gâchée pour de nombreuses raisons mais il est probable qu'une soit réellement en cause. Par exemple, si l'effet saccadé est causé par le ramasse miette traitant de gros morceaux de données à chaque frame, will-change: transform n'aura aucun effet positif. Au contraire, cette déclaration augmentera la pression sur la mémoire et pourrait même empirer le phénomène.
Je ne me souviens pas qui a énoncé « Si vous ne l'avez pas mesuré, ce n'est pas lent » mais cette phrase résonne en moi même si se concentrer sur la mesure peut mener à la Frénésie du Microbenchmark™️.
Note : pour le reste de ce billet, je vais parler d'optimisations en terme de vitesse mais tout ceci s'applique à d'autres types d'optimisations comme la réduction de l'empreinte mémoire.
Microbenchmarks
J'ai noté que récemment une grande attention était portée vers les microbenchmarks. Dans un microbenchmark, on essaie de départager deux approches en les exécutant plusieurs milliers de fois en isolation pour déterminer quelle solution est la plus rapide.
Comprenez-moi bien, les microbenchmarks ont une utilité, j'en ai même écrit et comme beaucoup d'autres avant moi. Ce sont des outils intéressants en particulier avec des frameworks comme BenchmarkJS qui permet d'obtenir des nombres statistiquement signifiants. En revanche, les frameworks de benchmark ne sont d'aucune aide pour s'assurer que votre benchmark a réellement un sens. Si vous ne connaissez pas ce que vous êtes en train de tester, les résultats peuvent mener à une mauvaise interprétation. Par exemple, dans mon billet sur le deep-cloning, je vérifiais les performances de const copyOfX = JSON.parse(JSON.stringify(x)). Il s'avère que V8 possède un cache d'objets. Le fait de réutiliser la même valeur x fois dans les tests a faussé les résultats. En réalité, je testais le cache plus qu'autre chose. Et si Mathias n'avait pas lu mon article, je ne l'aurais jamais découvert.
Compromis
Imaginons que vous ayez écrit ou trouvé un microbenchmark avec un sens. Il montre que vous devriez plutôt utiliser l'approche A au lieu de l'approche B. Il est important de comprendre que passer de B à A ne va pas uniquement rendre le code plus rapide. Quasiment toutes les optimisations de performance sont un compromis entre la vitesse et autre chose. Dans la plupart des cas, vous abandonnez un peu de lisibilité, d'expressivité et/ou d'idiomatisme. Ces propriétés ne se verront pas dans vos mesures pour autant il ne faut pas les ignorer. Le code devrait être écrit pour les humain·es (ce qui inclut le/la futur·e vous) mais pas l'ordinateur.
C'est là où les microbenchmarks nous abusent. Être capable de réaliser une opération plus rapidement ne signifie pas que le compromis en terme d'expressivité soit valable. En se basant sur des résultats de microbenchmarks, certaines personnes prendront pour évident que A est mieux que B et donc que vous devriez toujours mettre en œuvre A. C'est ainsi que la poudre de perlimpinpin est faite. Une partie du problème vient du fait qu'il est difficile de quantifier l'expressivité. À quel point un bout de code doit-il être plus rapide pour justifier une perte de lisibilité ? 10% ? 20% ?
Un point à propos de l'analyse statique et des transpilers s'impose. Il est possible d'écrire du code lisible et idiomatique tout en délivrant une version moins lisible et plus performante en production. Des outils comme @babel/present-env permettent d'écrire du JavaScript moderne et idiomatique sans avoir à se soucier de la prise en charge par les navigateurs et des implications en terme de performance. Le compromis ici se fait sur la taille et l'impénétrabilité du code généré. Certaines fonctionnalités ne peuvent être transformées qu'avec une importante augmentation de la taille du code ce qui détériore les temps de téléchargement et de compilation. La transformation des générateurs est un exemple extrême de ce phénomène. Un exécuteur de générateur doit être ajouté tout en rendant les fonctions génératrices significativement plus lourdes. Une fois encore, ce n'est pas une raison pour ne pas utiliser les générateurs ou pour ne pas les transformer. En revanche, c'est une information importante pour prendre une décision. Il s'agit encore et toujours de faire des compromis.

Budgets
Dans ce domaine, les budgets peuvent aider. Il est important de budgétiser différents aspects de votre projet. Pour les applications web, les préconisations RAIL constitue un choix populaire. Si vous souhaitez construire une application tournant à 60 images par seconde, vous avez 16ms par frame. Pour produire une interface qui paraît fluide, il faut répondre visuellement aux action des utilisateur·rices en moins de 100ms. À partir du moment où vous avez des budgets, vous pouvez profiler votre application et vérifier si vous restez dans les limites fixées. Et si ce n'est pas le cas, vous savez par où commencer les travaux d'optimisation.
Les budgets contextualisent les coûts. Imaginons que vous ayez un bouton dans votre interface qui lorsqu'il est utilisé entraîne la récupération avec fetch() et l'affichage à l'écran des dernières données liées aux stocks. Avec l'appel réseau, le traitement des données et le rendu, le délai entre le clic de l'utilsateur·rice et l'affichage est de 60ms. Nous somme parfaitement dans les préconisations RAIL abordées plus haut avec même une marge de 40ms ! Si vous considérez l'utilisation d'un worker pour le traitement des données, la communication entre les fils d'exécution impliquera un délai supplémentaire. Par expérience, ce délai est de l'ordre d'une frame (16ms) ce qui donne un total de 76ms.
Si vous aviez à prendre une décision avec un état d'esprit microbenchmark — en regardant uniquement les nombres sans contexte — la solution à base de workers vous paraîtra une mauvaise idée. Cependant, la vraie question n'est pas « Quelle est la solution la plus rapide ? » mais plutôt « Quel compromis puis-je faire ? » ou encore « Mon budget me permet-il de le faire ? » Dans l'exemple du worker, nous payons 16ms mais cette dépense rentre facilement dans les 40ms de marge par rapport à notre budget RAIL. Ce que nous obtenons en retour dépend de votre perspective; dans cet exemple je souhaite me concentrer sur la robustesse. Si le serveur envoie une énorme structure JSON liée aux stocks, le décodage prendra un temps considérable pendant lequel le main thread sera bloqué. En décodant et traitant les données dans un worker, le main thread sera épargné et l'usage de l'application restera fluide.

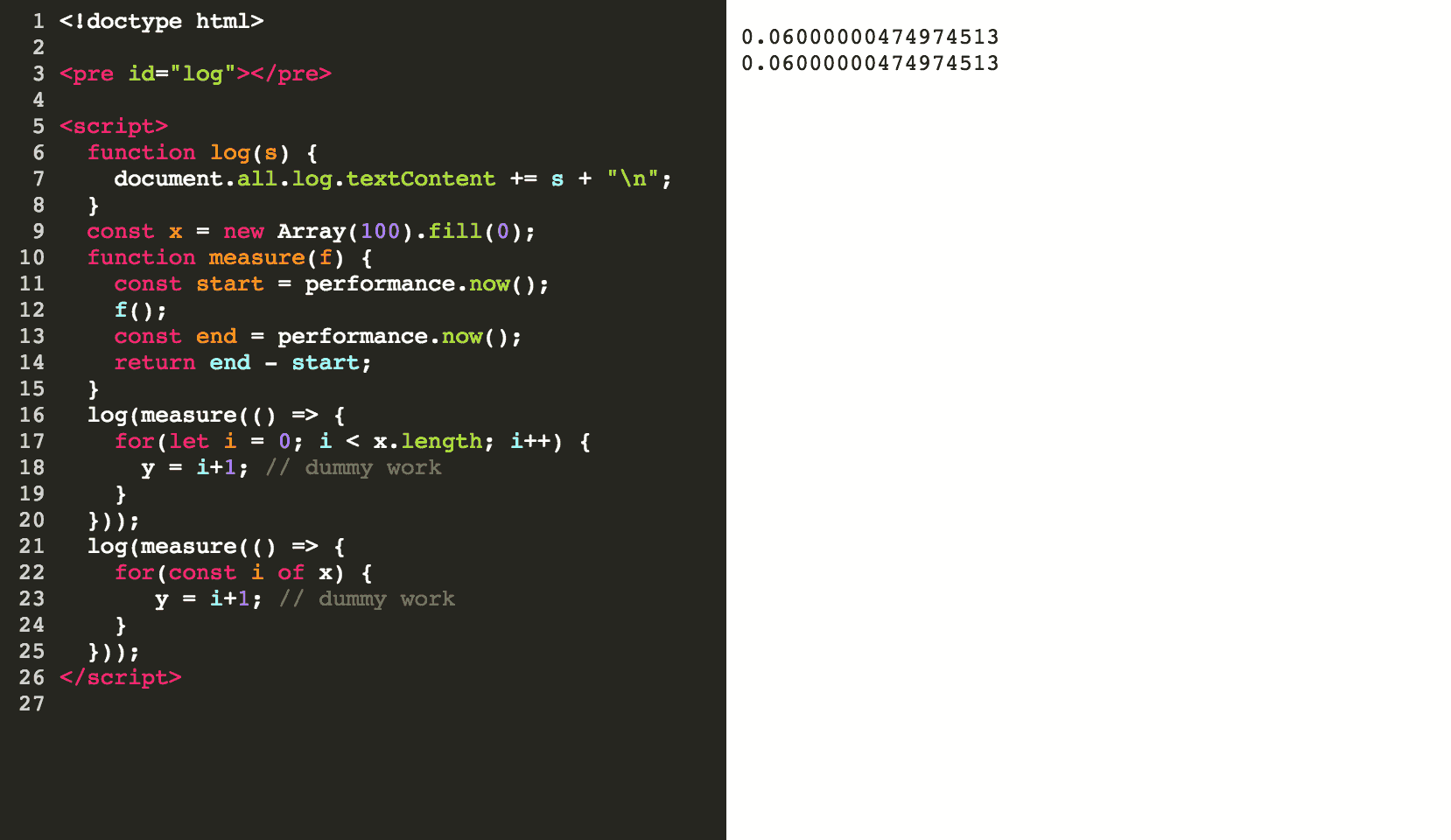
Prenons un autre exemple : jusqu'à il y a un an environ, utiliser une boucle for of pour parcourir un tableau était 17 fois plus lent qu'une boucle for classique (Note : six-speed a été mis en place en avril 2017. Depuis, de nombreux changements ont été apportés à V8 et Babel). À cause de ces résultats, certaines personnes évitent toujours les boucles for of.
Penchons nous sur des chiffres concrets : en parcourant un tableau de 100 éléments dans Chrome 55 (sorti en décembre 2016, avant le lancement de six-speed) avec un boucle for of puis un boucle for classique, j'obtiens :
- boucle
for of: 134µs - boucle
forclassique : 65µs
Sans conteste, la boucle for classique est plus rapide (dans Chrome 55) mais la boucle for of donne une vérification implicite des limites et rend le corps de la boucle plus lisibe en évitant l'utilisation d'un index. Y'a t il un intérêt à gagner ~60µs ? ça dépend mais la plupart du temps la réponse est non. Si vous utilisez des boucles for of dans un chemin critique (comme du code qui construit chaque frame dans une application WebGL), c'est peut-être le cas. Cependant, si vous ne parcourez que quelques dizaines d'éléments lorsque l'utilisateur·rice clique sur un bouton, je ne m'embêterais même pas à penser aux performances. Je choisis toujours la lisibilité. Et pour information, dans Chrome 70, les deux types de boucle ont exactement les mêmes performances. Un grand merci à l'équipe travaillant sur V8 !
Ça dépend (du contexte)
Bref, il n'existe aucune optimisation de performance qui soit toujours bonne. En fait, il n'y a pratiquement aucune optimisation de performance qui soit généralement bonne. Les pré-requis techniques, les audiences, les appareils et les priorités sont trop différentes d'un contexte à un autre. Ça dépend. Si vous voulez mon conseil, voici comme j'essaie d'aborder les optimisations :
- Définir un budget
- Mesurer
- Optimiser les parties qui explosent le budget
- Prendre une décision en tenant compte du contexte